Week 7 [Fri, Feb 17th] - Topics
Guidance for the item(s) below:
While the next few topics are optional, we recommend that you have a quick look anyway, just so that you know their existence at least.
Guidance for the item(s) below:
JavaFX is not required for this module as we strongly discourage you from creating a GUI app. If you are still interest to learn JavaFX, given below is a link to some tutorials.
Javadoc
Guidance for the item(s) below:
You'll need to add JavaDoc comments to the iP code this week. Let's learn how to do that.
Can explain JavaDoc
JavaDoc is a tool for generating API documentation in HTML format from comments in the source code. In addition, modern IDEs use JavaDoc comments to generate explanatory tooltips.
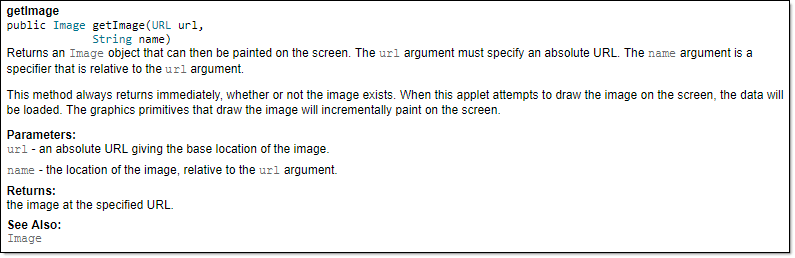
An example method header comment in JavaDoc format (adapted from Oracle's Java documentation)
/**
* Returns an Image object that can then be painted on the screen.
* The url argument must specify an absolute {@link URL}. The name
* argument is a specifier that is relative to the url argument.
* <p>
* This method always returns immediately, whether or not the
* image exists. When this applet attempts to draw the image on
* the screen, the data will be loaded. The graphics primitives
* that draw the image will incrementally paint on the screen.
*
* @param url an absolute URL giving the base location of the image
* @param name the location of the image, relative to the url argument
* @return the image at the specified URL
* @see Image
*/
public Image getImage(URL url, String name) {
try {
return getImage(new URL(url, name));
} catch (MalformedURLException e) {
return null;
}
}
Generated HTML documentation:
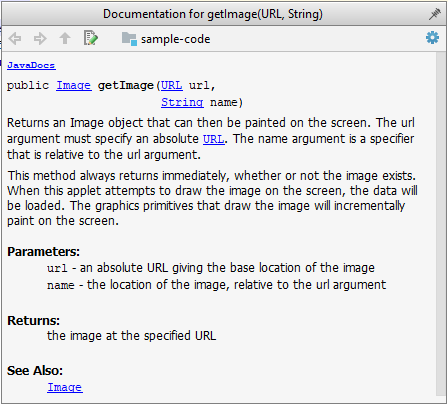
Tooltip generated by Intellij IDE:
Guidance for the item(s) below:
This is the final installment of the code quality topics. As you are learning about JavaDoc comments this week, you can also learn these guidelines to write better code comments.
Guidance for the item(s) below:
Modern software projects, and your tP, make heavy use of build/CI/CD tools The topics below give you an overview of those tools, to prepare you to start using them yourself.
Guidance for the item(s) below:
Let's learn how to merge a PR on GitHub; you need to do that in the tP later, and you'll be practicing PR merging in the iP this week.
Can review and merge PRs on GitHub
Let's look at the steps involved in merging a PR, assuming the PR has been reviewed, refined, and approved for merging already.
Preparation: If you would like to try merging a PR yourself, you can create a dummy PR in the following manner.
- Fork any repo (e.g., samplerepo-pr-practice).
- Clone in to your computer.
- Create a new branch e.g., (
feature1) and add some commits to it. - Push the new branch to the fork.
- Create a PR from that branch to the
masterbranch in your fork. Yes, it is possible to create a PR within the same repo.
1. Locate the PR to be merged in your repo's GitHub page.
2. Click on the Conversation tab and scroll to the bottom. You'll see a panel containing the PR status summary.
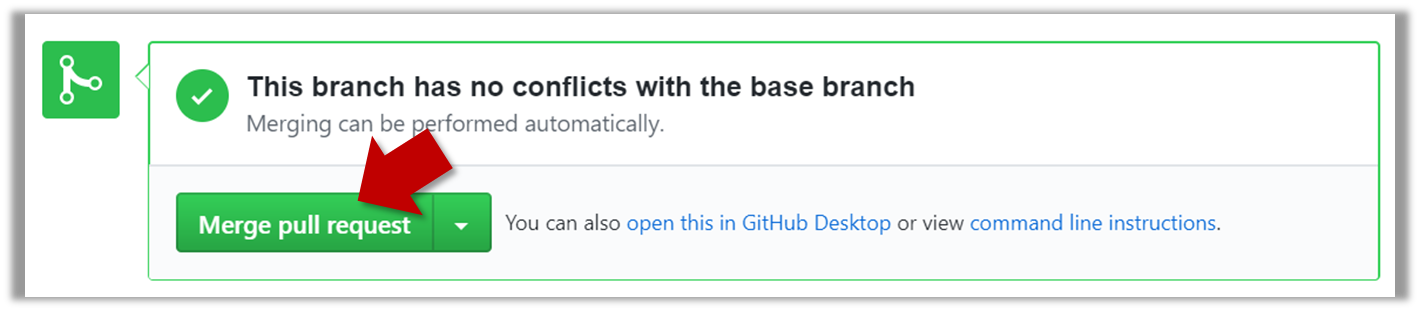
3. If the PR is not merge-able in the current state, the Merge pull request will not be green. Here are the possible reasons and remedies:
- Problem: The PR code is out-of-date, indicated by the message This branch is out-of-date with the base branch. That means the repo's
masterbranch has been updated since the PR code was last updated.- If the PR author has allowed you to update the PR and you have sufficient permissions, GitHub will allow you to update the PR simply by clicking the Update branch on the right side of the 'out-of-date' error message. If that option is not available, post a message in the PR requesting the PR author to update the PR.
- Problem: There are merge conflicts, indicated by the message This branch has conflicts that must be resolved. That means the repo's
masterbranch has been updated since the PR code was last updated, in a way that the PR code conflicts with the currentmasterbranch. Those conflicts must be resolved before the PR can be merged.- If the conflicts are simple, GitHub might allow you to resolve them using the Web interface.
- If that option is not available, post a message in the PR requesting the PR author to update the PR.
3. Merge the PR by clicking on the Merge pull request button, followed by the Confirm merge button. You should see a Pull request successfully merged and closed message after the PR is merged.
- You can choose between three merging options by clicking on the down-arrow in the Merge pull request button. If you are new to Git and GitHub, the
Create merge commitoptions are recommended.
Next, sync your local repos (and forks). Merging a PR simply merges the code in the upstream remote repository in which it was merged. The PR author (and other members of the repo) needs to pull the merged code from the upstream repo to their local repos and push the new code to their respective forks to sync the fork with the upstream repo.
Guidance for the item(s) below:
Next, you will learn a workflow called the 'Forking Flow', which combines the various Git and GitHub techniques you have been learning over the past few weeks. It is also the workflow you will use in the tP.
Can explain forking workflow
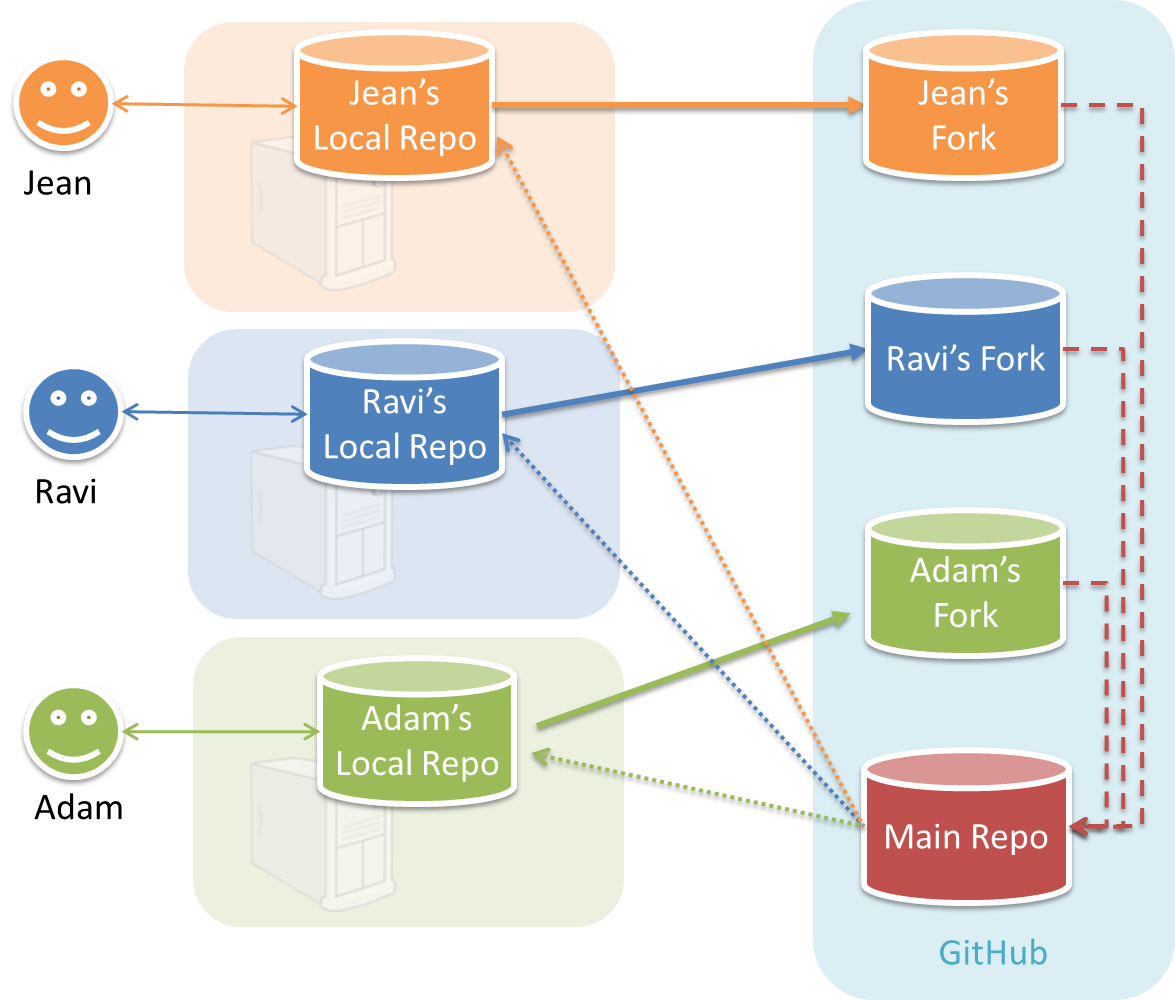
In the forking workflow, the 'official' version of the software is kept in a remote repo designated as the 'main repo'. All team members fork the main repo and create pull requests from their fork to the main repo.
To illustrate how the workflow goes, let’s assume Jean wants to fix a bug in the code. Here are the steps:
- Jean creates a separate branch in her local repo and fixes the bug in that branch.
Common mistake: Doing the proposed changes in themasterbranch -- if Jean does that, she will not be able to have more than one PR open at any time because any changes to themasterbranch will be reflected in all open PRs. - Jean pushes the branch to her fork.
- Jean creates a pull request from that branch in her fork to the main repo.
- Other members review Jean’s pull request.
- If reviewers suggested any changes, Jean updates the PR accordingly.
- When reviewers are satisfied with the PR, one of the members (usually the team lead or a designated 'maintainer' of the main repo) merges the PR, which brings Jean’s code to the main repo.
- Other members, realizing there is new code in the upstream repo, sync their forks with the new upstream repo (i.e. the main repo). This is done by pulling the new code to their own local repo and pushing the updated code to their own fork.
Possible mistake: Creating another 'reverse' PR from the team repo to the team member's fork to sync the member's fork with the merged code. PRs are meant to go from downstream repos to upstream repos, not in the other direction.
One main benefit of this workflow is that it does not require most contributors to have write permissions to the main repository. Only those who are merging PRs need write permissions. The main drawback of this workflow is the extra overhead of sending everything through forks.
Guidance for the item(s) below:
The activity in the section below can be skipped as you will be doing a similar activity in a coming tutorial.
Guidance for the item(s) below:
Git is considered a DRCS. Read the topic below to learn what that means and how it differs from the alternative.
Can explain DRCS vs CRCS
RCS can be done in two ways: the centralized way and the distributed way.
Centralized RCS (CRCS for short) uses a central remote repo that is shared by the team. Team members download (‘pull’) and upload (‘push’) changes between their own local repositories and the central repository. Older RCS tools such as CVS and SVN support only this model. Note that these older RCS do not support the notion of a local repo either. Instead, they force users to do all the versioning with the remote repo.
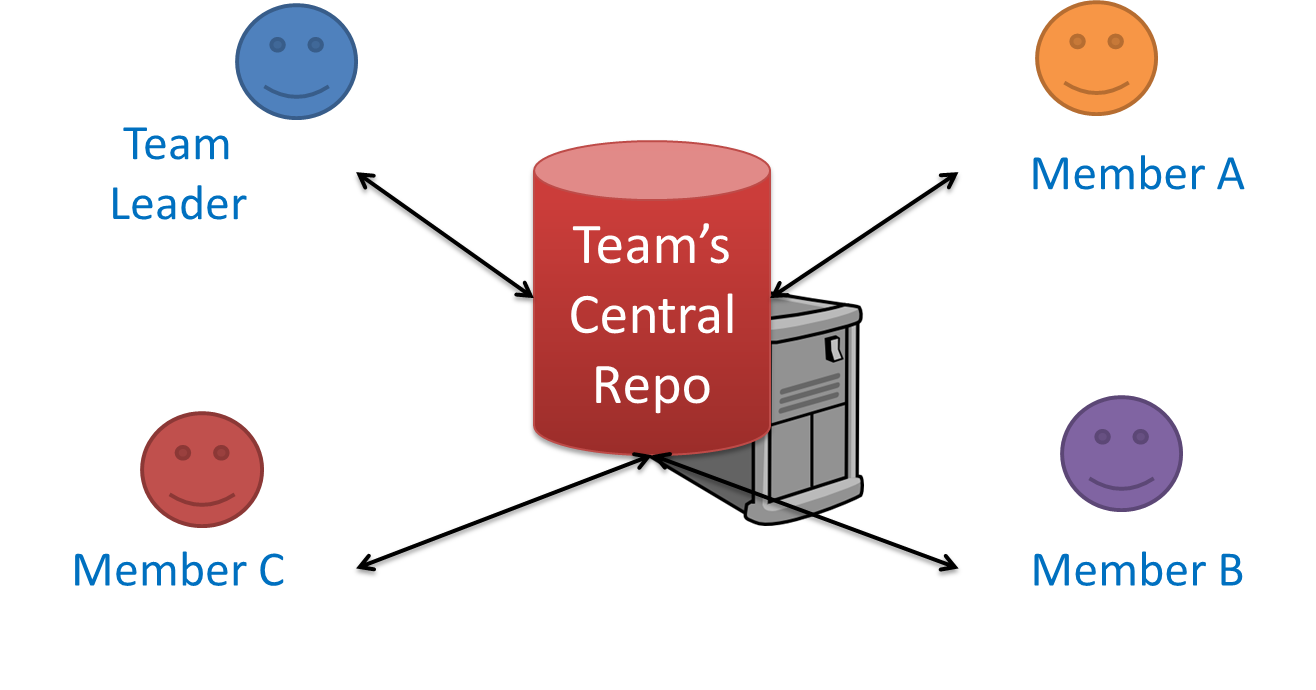
The centralized RCS approach without any local repos (e.g., CVS, SVN)
Distributed RCS (DRCS for short, also known as Decentralized RCS) allows multiple remote repos and pulling and pushing can be done among them in arbitrary ways. The workflow can vary differently from team to team. For example, every team member can have his/her own remote repository in addition to their own local repository, as shown in the diagram below. Git and Mercurial are some prominent RCS tools that support the distributed approach.
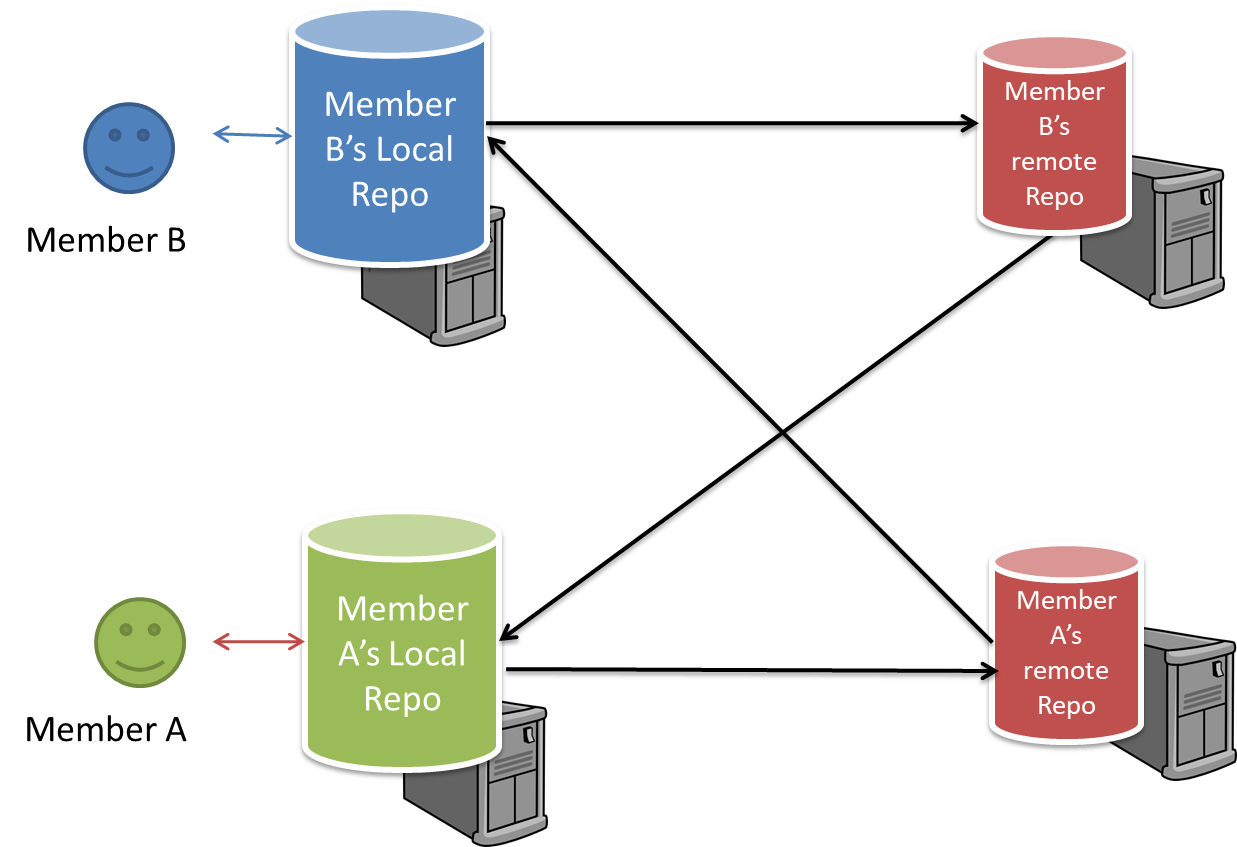
The decentralized RCS approach
Guidance for the item(s) below:
These are two workflows that are riskier (but simpler) than the forking flow. After following the forking flow for a while, you may switch to one of these, but at your own risk.