Week 12 [Fri, Mar 31st] - Topics
Guidance for the item(s) below:
Previously, you learned about equivalence partitions, a heuristic for dividing the possible test cases into partitions. But which test cases should we pick from each partition? Next, let us learn another heuristic which can addresses that problem.
Guidance for the item(s) below:
Earlier, you learned that can improve the test case quality. Even when applying them, the number of test cases can increase when the SUT takes multiple inputs. Let's see how we can deal with such situations.
Guidance for the item(s) below:
Testing is the first thing that comes to mind when you hear 'Quality Assurance' but there are other QA techniques that can complement testing. Let's first take a step back and take a look at QA in general, followed by a look at some other QA techniques.
Guidance for the item(s) below:
In a previous week, you learned about sequential and iterative ways of doing a software. Now, let us take a quick look at a couple of well-known processes used in the industry, both of which fall into a category called agile processes.
Can explain scrum
This description of Scrum was adapted from Wikipedia [retrieved on 18/10/2011], emphasis added:
Scrum is a process skeleton that contains sets of practices and predefined roles. The main roles in Scrum are:
- The Scrum Master, who maintains the processes (typically in lieu of a project manager)
- The Product Owner, who represents the stakeholders and the business
- The Team, a cross-functional group who do the actual analysis, design, implementation, testing, etc.
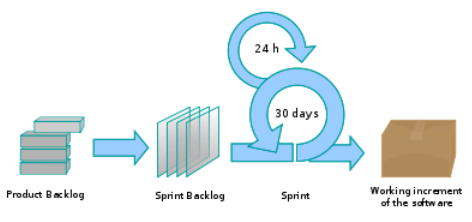
A Scrum project is divided into iterations called Sprints. A sprint is the basic unit of development in Scrum. Sprints tend to last between one week and one month, and are a timeboxed (i.e. restricted to a specific duration) effort of a constant length.
Each sprint is preceded by a planning meeting, where the tasks for the sprint are identified and an estimated commitment for the sprint goal is made, and followed by a review or retrospective meeting, where the progress is reviewed and lessons for the next sprint are identified.
During each sprint, the team creates a potentially deliverable product increment (for example, working and tested software). The set of features that go into a sprint come from the product backlog, which is a prioritized set of high level requirements of work to be done. Which backlog items go into the sprint is determined during the sprint planning meeting. During this meeting, the Product Owner informs the team of the items in the product backlog that he or she wants completed. The team then determines how much of this they can commit to complete during the next sprint, and records this in the sprint backlog. During a sprint, no one is allowed to change the sprint backlog, which means that the requirements are frozen for that sprint. Development is timeboxed such that the sprint must end on time; if requirements are not completed for any reason they are left out and returned to the product backlog. After a sprint is completed, the team demonstrates the use of the software.
Scrum enables the creation of self-organizing teams by encouraging co-location of all team members, and verbal communication between all team members and disciplines in the project.
A key principle of Scrum is its recognition that during a project the customers can change their minds about what they want and need (often called requirements churn), and that unpredicted challenges cannot be easily addressed in a traditional predictive or planned manner. As such, Scrum adopts an empirical approach—accepting that the problem cannot be fully understood or defined, focusing instead on maximizing the team’s ability to deliver quickly and respond to emerging requirements.
Daily Scrum is another key scrum practice. The description below was adapted from https://www.mountaingoatsoftware.com (emphasis added):
In Scrum, on each day of a sprint, the team holds a daily scrum meeting called the "daily scrum.” Meetings are typically held in the same location and at the same time each day. Ideally, a daily scrum meeting is held in the morning, as it helps set the context for the coming day's work. These scrum meetings are strictly time-boxed to 15 minutes. This keeps the discussion brisk but relevant.
...
During the daily scrum, each team member answers the following three questions:
- What did you do yesterday?
- What will you do today?
- Are there any impediments in your way?
...
The daily scrum meeting is not used as a problem-solving or issue resolution meeting. Issues that are raised are taken offline and usually dealt with by the relevant subgroup immediately after the meeting.
Can explain XP
The following description was adapted from the XP home page, emphasis added:
Extreme Programming (XP) stresses customer satisfaction. Instead of delivering everything you could possibly want on some date far in the future, this process delivers the software you need as you need it.
XP aims to empower developers to confidently respond to changing customer requirements, even late in the life cycle.
XP emphasizes teamwork. Managers, customers, and developers are all equal partners in a collaborative team. XP implements a simple, yet effective environment enabling teams to become highly productive. The team self-organizes around the problem to solve it as efficiently as possible.
XP aims to improve a software project in five essential ways: communication, simplicity, feedback, respect, and courage. Extreme Programmers constantly communicate with their customers and fellow programmers. They keep their design simple and clean. They get feedback by testing their software starting on day one. Every small success deepens their respect for the unique contributions of each and every team member. With this foundation, Extreme Programmers are able to courageously respond to changing requirements and technology.
XP has a set of simple rules. XP is a lot like a jig saw puzzle with many small pieces. Individually the pieces make no sense, but when combined together a complete picture can be seen. This flow chart shows how Extreme Programming's rules work together.
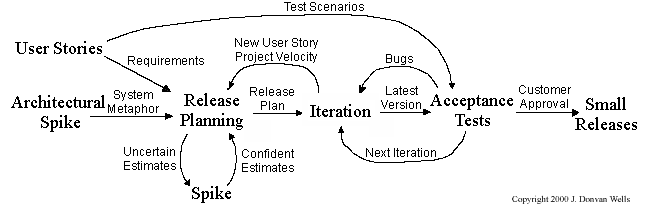
Pair programming, CRC cards, project velocity, and standup meetings are some interesting topics related to XP. Refer to extremeprogramming.org to find out more about XP.